
本記事は以下のApplication Insightsに関するトレーニングの内容を要約したものです。

Application Insightsとは?
一言でいうと、「アプリケーション専用の、高性能な監視センター(または健康診断センター)」です。
これはAzureの「Azure Monitor」という大きな監視サービスの一部で、特にアプリケーションのパフォーマンス監視(APM)に特化しています。
APMの2つの役割
APMは、アプリの健康状態を2つの側面から監視します。
プロアクティブ(事前の監視)
ユーザーから「サイトが重い」と苦情が来る前に、パフォーマンスの低下を検知します。
リアクティブ(事後の分析)
障害が発生した後に、「なぜ落ちたのか?」を特定するため、実行時のデータをさかのぼって調査(デバッグ)します。
何を監視・収集するのか?
この「監視センター」は、アプリから送られてくる様々な情報(=テレメトリ)を集めて分析します。
1. パフォーマンスデータ (APMの基本)
- リクエスト: どのページが、どれくらい呼ばれているか。応答時間は? エラー率は?
- 依存関係: アプリが呼び出しているDBや外部APIの応答時間は?
- 例外: サーバー側(プログラム)やブラウザ側(JavaScript)で、どんなエラーが何件起きているか。
2. ユーザー体験データ (RUM)
- ページビュー: ユーザーのブラウザで、ページの読み込みに実際に何秒かかったか。
- AJAX呼び出し: ページ内で裏で動いている通信(例: 検索候補の表示)の速度。
- ユーザー数: 何人のユーザーが使っているか。
3. インフラデータ
パフォーマンスカウンター: サーバーのCPU使用率、メモリ使用量など。
4. ログとカスタムデータ
- トレースログ: 開発者がコードに書いたデバッグ用のログ(ILoggerなど)。これをリクエスト情報と紐づけて見られるのが非常に強力です。
- カスタムイベント: 「購入ボタンが押された」「ゲームで勝利した」など、ビジネス固有のデータを記録できます。
特に便利な機能
機能群を表にします。
| 機能名 | 現場での使われ方(イメージ) |
| ライブ メトリック | 「生中継の心電図」。今まさに動いているアプリのCPUやリクエスト数をリアルタイムで監視します。 |
| 可用性 | 「世界中からのロボット監視員」。前回解説した、外からURLを叩いて死活監視する機能です。 |
| GitHub/Azure DevOps 統合 | エラーを見つけたら、その場でワンクリックで「バグ修正チケット」を作成できます。 |
| 使用法 | 「人気機能ランキング」。どの画面が一番使われていて、どのボタンが押されていないかを分析します。 |
| スマート検出 | 「AIによる異常検知アラート」。普段と違う動き(急なエラー増加や速度低下)を自動で検知してくれます。 |
| アプリケーション マップ | 「システムの路線図(レントゲン)」。前回解説した、システム全体のつながりとボトルネックを可視化します。 |
| 分散トレース | 「荷物の追跡サービス」。1つのリクエストが、複数のサービス(Web→API→DB)をどう旅したかを最初から最後まで追跡します。 |
どうやって監視を始めるか?
- 実行時 (Runtime): 自動インストルメンテーション。コード変更なしで、Azure側で設定をONにするだけ。
- 開発時 (Development): 手動インストルメンテーション。コードにSDK(監視ライブラリ)を追加する。カスタムデータも取れる。
- その他: Webページ(ブラウザ側)、モバイルアプリ、可用性テストなど、目的に応じた方法があります。
2.ログベースのメトリックを検出する
核心:2つのメトリックの違い
Application Insightsには、データを扱う「2つのアプローチ」があります。これを「レシート(領収書)」と「家計簿」の関係でイメージするとわかりやすくなります。
1. ログベースのメトリック (Log-based metrics)
- イメージ: 「レシートの山」です。
- 仕組み: イベント(ログ)を1つ1つすべて保存しておき、グラフを表示するたびに**「えーっと、レシートが全部で何枚あるかな?」と毎回計算(クエリ)**します。
- メリット: 「誰が、いつ、何を買ったか」という**詳細な分析(ディメンション分析)**ができます。
- デメリット: データ量が多いと計算に時間がかかります。また、データ量を減らすために一部のログを間引く(サンプリングする)と、全体の件数が不正確になります。
2. 標準メトリック (Standard metrics / Pre-aggregated metrics)
- イメージ: 「家計簿の合計欄」です。
- 仕組み: データが発生した時点(またはAzureに届いた瞬間)に、「今は1分間で100件アクセスがあった」という集計結果だけを記録します。
- メリット: すでに計算済みなので、表示が爆速です。また、後で元のログを捨ててしまっても「合計数値」は記録されているので、数値が正確です。アラートやダッシュボードに向いています。
- デメリット: 「合計」しかないので、「エラーが出た、その瞬間のユーザーIDは?」といった深い分析には向きません。
比較まとめ
実務では、以下のように使い分けます。
| 特徴 | 標準メトリック (Standard) | ログベースのメトリック (Log-based) |
| 別名 | 事前集計メトリック (Pre-aggregated) | 従来のメトリック |
| 主な用途 | ダッシュボード監視、アラート発報 | トラブルシューティング、詳細分析 |
| パフォーマンス | 非常に高速 (集計済みのため) | クエリ実行が必要なため、少し遅い |
| サンプリング | 影響を受けない (正確な値を維持) | 影響を受ける (値が近似値になる) |
| コスト | データ量が少ないため安価 | 全ログを保存すると高額になりがち |
| 情報の深さ | 浅い (数値のみ) | 深い (個別の属性情報まで見れる) |
なぜ「サンプリング(間引き)」が重要なのか?
大規模なアプリでは、すべてのログを保存するとコストが膨大になるため、例えば「10件に1件だけ保存する(サンプリング)」という設定をよく行います。
- ログベースの場合: 保存された「1件」しか見えないため、計算上はアクセス数が「1/10」になったように見えてしまうリスクがあります(実際は補正計算を行いますが、誤差が出ます)。
- 標準メトリックの場合: 「ログを捨てる前」にカウントだけ済ませておく仕組みです。たとえログの実体を9割捨てたとしても、「合計アクセス数は100件でした」という数値(メトリック)は正確に残ります。
テキスト内の「SDK」に関する記述の意味:
新しいバージョンのSDKを使うと、アプリ側(送信前)で集計を行ってくれるため、通信量を減らしつつ、正確な数値をAzureに送ることができるというメリットを説明しています。
3.監視のためにアプリをインストルメント化する
アプリケーションを「インストルメント化」する2つの方法
監視を始めるには、アプリに「テレメトリ(データ)を送る機能」を持たせる必要があります。大きく分けて「全自動」と「手動」の2つのルートがあります。
1. 自動インストルメンテーション (Auto-instrumentation)
- イメージ: **「外付けのアタッチメント」**です。
- 特徴: アプリのソースコード(プログラムの中身)を書き換える必要がありません。Azureポータルの設定スイッチをオンにするか、サーバーにエージェントを入れるだけで監視が始まります。
- メリット: とにかく楽です。コードに触らないのでバグを生むリスクも低いです。
- デメリット: 「標準的なデータ」しか取れません。「このボタンを押した回数」のような細かいカスタムデータは取れません。
- 推奨: まずはこれを試します。 これで要件が満たせるなら、それがベストプラクティスです。
2. 手動インストルメンテーション (Manual instrumentation)
- イメージ: **「エンジン内部への配線」**です。
- 特徴: プログラマーがコードの中に監視用のライブラリ(SDK)を書き込みます(NuGetやnpmでインストール)。
- メリット: 自由自在です。「この処理の、この変数の値を記録したい」といった細かい制御が可能です。
- デメリット: コードを書く手間がかかります。また、ライブラリのバージョンアップ管理を自分でする必要があります。
- いつ使う?: 自動化が対応していない言語を使う場合や、独自のカスタムデータを取りたい場合に使います。
2つの「手動」の手法:クラシック vs モダン
手動でコードを書く場合、さらに2つの選択肢が提示されていますが、ここが少しややこしい部分です。
1.Application Insights SDK (クラシック)
- 昔からあるマイクロソフト独自のツールです。
- 機能は豊富ですが、マイクロソフト製品に特化しています。
2.OpenTelemetry Distros (モダン・業界標準)
- GoogleやMicrosoftなどが協力して作った**「業界統一規格」**です。
- 今後はこっちが主流になります。ベンダー(AzureやAWSなど)に依存しない書き方ができます。
- Distro (ディストロ) とは、その統一規格をAzureで使いやすくパッケージした「Azure版OpenTelemetry」のことです。
要点: 新規で開発するなら、業界標準である OpenTelemetry ベースのものを選ぶのが今のトレンドです。
用語の翻訳(App Insights vs OpenTelemetry)
業界標準の OpenTelemetry に移行するにあたり、これまで Application Insights で使われていた言葉(方言)が、標準語(OpenTelemetry語)に置き換わります。表の意味を噛み砕きます。
| Application Insights (旧・方言) | OpenTelemetry (新・標準語) | 意味のイメージ |
| 要求 (Request) | サーバー スパン (Server Span) | 外部からアプリへのアクセス(入口) |
| 依存関係 (Dependency) | クライアント スパン (Client Span) | アプリからDBや外部APIへのアクセス(出口) |
| 操作 ID (Operation ID) | トレース ID (Trace ID) | 一連の処理全体を追跡する共通ID |
| ログ (Log) | ログ (Log) | (これは変わりません) メッセージ記録 |
※ スパン (Span) とは、「ある処理の開始から終了までの区間」を指す言葉です。
3章まとめ
このページの主旨は以下の通りです。
- まずは「自動 (コードなし)」 で監視できないか検討せよ。
- 無理なら 「手動 (SDK導入)」 を行え。
- 手動でやるなら、今後はマイクロソフト独自方式ではなく、「OpenTelemetry (業界標準)」 の用語や仕組みを理解しておいたほうがいいよ。
4.可用性テストを選択する
可用性テストとは?
「世界中のロボットが、あなたのサイトにアクセスし続ける機能」です。
- 仕組み: Azureが持っている世界中のサーバー(日本、アメリカ、ヨーロッパなど)から、あなたのWebサイトのURLに定期的にアクセス(Ping)します。
- 目的: 「サイトが落ちていないか」「表示が遅すぎないか」をチェックします。
- 特徴: アプリの中にコードを書く必要はありません。公開されているURLさえあればチェック可能です。
テストの種類(3つの選択肢)
実質的に覚えるべきは「標準テスト」と「カスタム」の2つです。「URL ping」は廃止予定だからです。
1. 標準テスト (Standard test) 【★推奨】
- 概要: 「このURL、開ける?」というシンプルなテストの進化版です。
- できること:
- ページが正常に返ってくるか(200 OKか)。
- SSL証明書(https)の期限が切れていないか。
- GETだけでなく、POST(データ送信)などもテスト可能。
- 用途: トップページやAPIのエンドポイントが生きているかの確認。
2. カスタム TrackAvailability テスト
- 概要: **「プログラムで書く、複雑なシナリオテスト」**です。
- できること: 単純なURLアクセスだけでなく、複雑なロジックを実行して、その結果(成功/失敗)を TrackAvailability() という命令でAzureに送ります。
- 例:「ログイン画面を開く」→「IDを入れる」→「ログインボタンを押す」→「マイページが表示されるか確認する」といった一連の流れをテストしたい場合に使用します(通常、Azure Functionsなどでテストコードを動かします)。
- 用途: 買い物カゴ機能やログイン機能など、重要なビジネスロジックの監視。
3. URL ping テスト (Classic) 【⚠️廃止予定】
- 概要: 昔からある古いタイプです。「標準テスト」の前身です。
- 注意: 2026年9月30日に廃止されます。今から新しく設定するなら、これを選ぶ理由はありません。「標準テスト」を使いましょう。
4章まとめ
| テスト名 | 特徴 | 今後のアクション |
| 標準テスト | 今の主流。 URL単体の生存確認。SSL確認も可。 | これを使う |
| カスタムテスト | 複雑な処理用。 ログインなどのシナリオ監視。 | 必要に応じて使う |
| URL ping (Classic) | 古い。 標準テストとほぼ同じだが機能が古い。 | 使わない (移行する) |
5.アプリケーション マップを使用してアプリのパフォーマンスのトラブルシューティングを行う
アプリケーション・マップとは?
「どこでエラーが起きているか、一目でわかる地図」です。
現代のアプリは、「Webサーバー」「データベース」「外部API」「ストレージ」など、たくさんのパーツが連携して動いています。これらがどう繋がっていて、どこが詰まっている(ボトルネック)のかを自動で図解してくれる機能です。
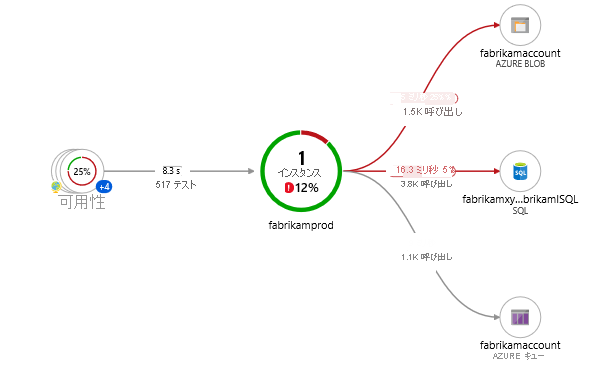
この画像がまさにマップの典型例です。
1. 真ん中の円(fabrikamprod)
- これがあなたのアプリ本体(コンポーネント)です。
- 緑の円は「正常」、赤が混じっていると「エラーあり」です。画像では少し赤くなっているので、「何か問題があるな」と直感的に分かります。
2. 右側の矢印とアイコン(依存関係)
- アプリが接続している外部サービスです(SQLデータベース、Azure Blobストレージなど)。
- 矢印の上の数字は「応答時間(平均何ミリ秒かかったか)」です。ここが異常に長いと、「アプリではなくDBが遅いんだな」と犯人が特定できます。
3. 左側の地球儀(可用性)
前のページで解説した「可用性テスト(外形監視)」の結果です。外から見てサイトが生きているかが表示されます。
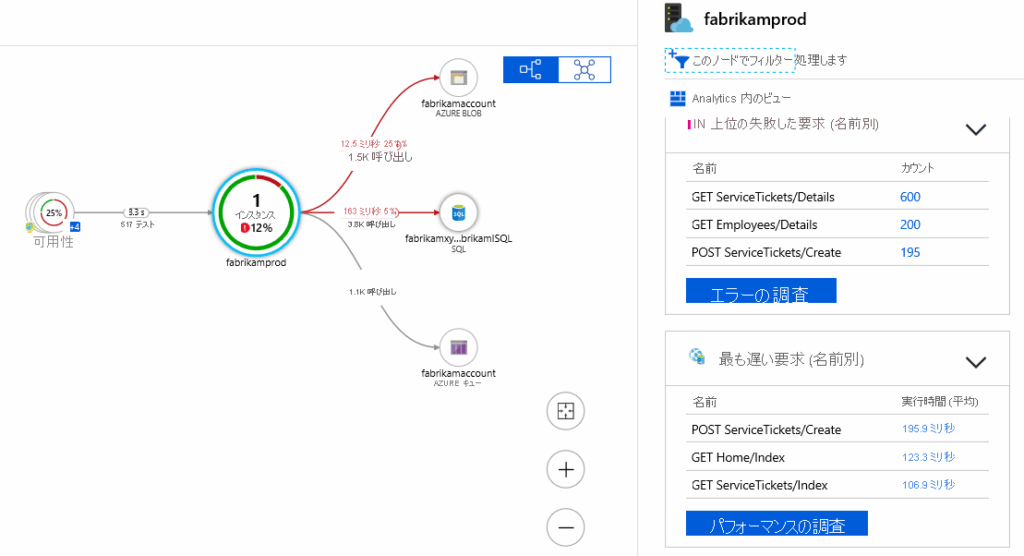
4. 右側のパネル(重要!)
- 真ん中の円をクリックすると表示されます。
- 「上位の失敗した要求」や「最も遅い要求」がランキングで出ます。
- 「エラーの調査」ボタンを押せば、そのまま原因の特定(ドリルダウン)に進めます。
専門用語の「現場的な」解釈
テキストにある少しややこしい用語を噛み砕きます。
1. コンポーネント (Component) vs 依存関係 (Dependency)
- コンポーネント:
- 「自分が管理しているコード」です。
- 例:Webアプリのサーバー、バックグラウンドの処理プログラムなど。
- あなたがSDKを入れて監視している主体です。
- 依存関係:
- 「利用している外部サービス」です。
- 例:SQL Database、Azure Storage、他社のAPIなど。
- これらの中身のコードは見えませんが、「呼び出して返ってくるまでの時間」や「エラーになったか」は計測できます。
2. クラウド ロール名 (Cloud Role Name)
- 「マップ上の名札」です。
- これが適切に設定されていないと、マップ上で複数のサーバーが「ひとまとめ」に表示されてしまったり、逆にバラバラになりすぎたりして、地図が役に立たなくなります。
- (※多くの開発者が最初に直面する、「マップが綺麗に表示されない」原因のNo.1がこの設定です)
つまり、どう使う機能なのか?
トラブルが起きた時の「最初の切り分け」に使います。
- マップを開く。
- 赤い矢印や赤い円を探す。
- 「SQLへの矢印が赤い」→「DBがおかしいぞ?」
- 「アプリの円だけ赤い」→「プログラムのバグか?」
- クリックして右側のパネルを見る。
- 「エラーの調査」ボタンを押して、具体的なログを見る。
6.概要
このモジュールでは、以下の方法について学習しました。
- Application Insights のしくみと、イベントとメトリックの収集方法について
- 監視用にアプリをインストルメント化し、可用性テストを実行
- アプリケーション マップを使用と、パフォーマンスの監視や問題のトラブルシューティング

コメント